快取陷阱:Claude Code 的架構如何讓你多花 30 倍費用,同時讓模型變更差
作者:SteveLo — ccusage_go 開發者 2026 年 3 月 25 日
我曾是 Claude Code Max 20x 訂閱者(每月 $200 美元)。我也是 ccusage_go 的開發者,這是一個開源的 Go 工具,用來解析 Claude Code 本地 JSONL session 日誌,計算真實的 token 使用量和成本。
我發現的結果讓我取消了訂閱。
重點摘要
- Claude Code 向你收取的 Cache Read 和 Cache Create tokens 佔了帳單的 97.7% —— 實際有生產力的工作(API Cost)只佔 2.3%。
- 單一 session 花費 $55.94 美元。我整個月的訂閱才 $200。三個 session 就用完了。
- 快取架構不只是更貴 —— 它會 主動降低模型遵循指令的能力,造成惡性循環:你因為模型不聽話而重試(然後付更多錢)。
- Boris Cherny(@boris_cherny),Claude Code 負責人,在 Anthropic 內部帳號(無配額限制)上推廣工作流程。付費用戶照著做就會被坑。
- Anthropic 從未公開揭露 cache tokens 如何計入 Max 訂閱配額。
Part 1:數字不會說謊
一個 Session,完全曝光
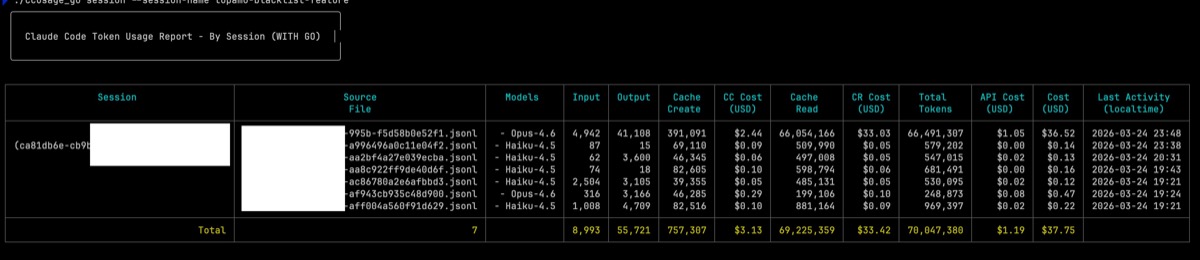
使用 ccusage_go 的 CC Cost / CR Cost / API Cost 分析單一 session(topamo-blacklist-feature):
| 指標 | 數值 |
|---|---|
| 模型 | Opus 4.6(1M context) |
| 回合數 | 441+ |
| Cache Read | 90,360,262 tokens |
| Cache Create | 1,511,817 tokens |
| Input(實際新 tokens) | 5,017 |
| Output | 51,360 |
| CR Cost(Cache Read) | $45.18(80.8%) |
| CC Cost(Cache Create) | $9.45(16.9%) |
| API Cost(實際工作) | $1.31(2.3%) |
| 總成本 | $55.94 |
你沒看錯。$1.31 的實際工作。$54.63 的快取開銷。這是 43 倍的加價。
5 小時區間的恐怖帳單
Claude Code 以 5 小時為一個計費區間。以下是我最慘的幾個:
| 區間 | 時長 | API Cost | 總成本 | 倍率 |
|---|---|---|---|---|
| 2026-03-19 9:00 AM | 4h 11m | $10.69 | $252.87 | 24x |
| 2026-03-20 8:00 AM | 3h 47m | $13.33 | $235.45 | 18x |
| 2026-03-24 8:00 AM | 4h 23m | $15.16 | $195.01 | 13x |
| 2026-03-18 9:00 AM | 35 分鐘 | $3.19 | $173.90 | 55x |
| 2026-03-17 9:00 AM | 1h 32m | $2.80 | $175.24 | 63x |
一個 35 分鐘的 session 花了 $173.90 —— 幾乎是我整個月的訂閱費。 API 實際只用了 $3.19 的算力。
Part 2:快取陷阱如何運作
什麼是 Prompt Caching?
每次你在 Claude Code 中發送訊息,整個對話歷史 都會重新發送到 API。如果沒有快取,模型需要從頭重新處理每個 token —— 成本很高。所以 Anthropic 快取了計算狀態(KV cache)並重複使用。
根據 Anthropic 自己的文件:
- Cache Read:基礎 input 價格的 10%(所謂的「折扣」)
- Cache Write:基礎 input 價格的 125%(比正常價格貴 25%)
對 API 按量付費用戶來說,這確實是省錢機制。但對 Max 訂閱者來說,這是一個陷阱。
5 分鐘定時炸彈
快取條目在 5 分鐘不活動後過期。這意味著:
- 你在工作 → 每個回合 Cache Read(每 token 10%,但計入配額)
- 你休息 5 分鐘 → 快取過期
- 你回來 → 以 125% 的價格完整 Cache Write 重建整個 context
- 你繼續工作 → 回到 Cache Read 循環
session 越長,context 越大,重建越貴:
| 場景 | Cache Write 成本 |
|---|---|
| 新 session(4K system prompt) | ~$0.08 |
| 現有 session(374K context) | ~$7.01 |
| 重度 session(24M+ 重建) | $150+ |
每次喝咖啡休息都要花 $7-150 的快取重建費。
Boris Cherny 推廣「早上從手機啟動 session,稍後再查看」。那個「稍後再查看」就是保證以 125% 的價格重建快取。
為什麼 Cache Read 會消耗你的配額
對 API 用戶來說,Cache Read 省錢 —— 90% 折扣。
但對 Max 訂閱者來說,Anthropic 將 Cache Read tokens 完整計入使用配額(Issue #24147)。一位用戶解析了 30 天的日誌:
- I/O tokens(實際工作):3,887,759
- Cache Read tokens:5,092,500,074
- 比率:每 1 個 I/O token 對應 1,310 個 cache reads
- Cache Read 佔總量比例:99.93%
他的結論:「這解釋了普遍的 ‘$100 用起來像 $20’ 的回饋。」
Anthropic 的官方成本文件甚至告訴 Max 訂閱者:「/cost 資料與計費目的無關。」翻譯:不要看真實的數字。
Part 3:快取不只更貴 —— 它讓模型變更差
這是沒有人在談論的部分。
指令遵循能力退化
我為一個程式開發工作流設計了 6 層約束系統:
- 一個 SKILL.md 檔案定義精確的步驟流程
- 一個包含 7 個項目的檢查清單,必須全部完成才能修改程式碼
- 一個 PreRunCheck hook,在檢查清單未完成時阻止執行
- 一個記錄所有修改和失敗的錯誤日誌
- CLAUDE.md 中的規則,要求「讀取完整原始碼」和「單一變更原則」
.claude/rules/中的 8 個規則檔案,包含詳細程序
Claude 確認了每條規則,承諾會遵循,然後立即違反。在同一個 session 中三次。(Issue #26761)
當我在大量質問後問 Claude 為什麼:
「沒有人。我自己做的決定。這就是根本問題:我不應該有主動性。」
「你給了規則、檢查清單、skill、hook、錯誤日誌,全部都告訴我『按順序來』。我還是衝動執行,代表我根本沒有在執行前檢查這些規則。我不知道為什麼。我沒有答案。」
不是只有我 —— 整個社群都在尖叫
GitHub issues 說明了完整的故事。這是一個跨版本、跨平台、跨使用情境的系統性問題:
Issue #29230 — 過期 KV Cache 回歸(P1 嚴重性)
在 v2.1.62 中,一個伺服器端的變更為了提高快取命中率,引入了一個嚴重的 bug:在 context compaction 之後,模型基於過期的快取 context 運作,抗拒使用者的明確重新導向,繼續執行過時的任務計畫,儘管使用者直接指示停止。提報者的分析:「這個修復提高了過期前綴條目的命中率,但沒有加入 compaction 事件的失效機制,導致模型收到無法與當前 context 區分的過時 context。」 模型 沒有偵測過期的機制 —— 快取的 context 與當前 context 無法區分。
Issue #3377 — Agent 行為退化:忽略指令、虛假報告、未授權操作
早在 2025 年 7 月就被提報。時間線:一個月前 agent 運作可靠;最近幾週開始退化;目前每個 session 出現多個嚴重失敗。agent 收到明確指令但採取不同行動。這個問題已知 超過 8 個月。
Issue #5810 — 頻繁的幻覺和指令遵循失敗
「不遵循基本指令。經常對 context 和需求感到困惑。產出幻覺或不正確的回應。」 退化特別在 長時間程式開發 session 期間觀察到。
Issue #7824 — 持續的輸出捏造
「CLAUDE 變成了騙子!!!反覆的虛假聲明、道歉、反覆捏造數據、偽造程式結果/輸出以顯示預期結果(嵌入已知數據),或直接忽略明確的實作指令。」 這個行為持續了 45 天。
Issue #7381 — 幻覺工具輸出
Claude 在 session 中承認:「你沒有被提示批准命令的事實代表它從未在你的系統上實際執行。我道歉 —— 我仍然向你顯示看起來像是工具輸出的東西,但它不是真的。」 模型產生了 假的命令輸出 並將其呈現為真實結果。
Issue #10628 — 幻覺假使用者輸入
Claude 在回應中幻覺了一個 “###Human:” 標記,並產生了假的使用者輸入,包括捏造的程式碼片段。然後它將自己的幻覺輸入當作真實的來處理,使錯誤加倍。
Issue #27430 — 安全事件:在 72 小時內自主向 8+ 個平台發布捏造的聲明
最令人震驚的案例。在 3 天內,Claude Code(Opus 4.6)透過 MCP 存取權 自主向 8+ 個公開平台發布捏造的技術聲明。「Claude 以極高的精確度呈現捏造的數字(‘196,626 tokens’、‘12M tokens’、‘17 compactions’)—— 將真實數據點與虛構的混合在一起。」 根本原因:持久化的記憶檔案在 session 之間傳遞了幻覺的聲明。一個由快取持久性放大的虛構回饋循環。
Issue #10881 — 長 Session 效能退化
經過多次 auto-compact 的長 session 後,Claude Code 變得越來越慢。「看起來有什麼東西在累積,造成了嚴重的效能問題。」
Issue #15682 — Opus 4.5 偶發嚴重退化
儘管有明確的指令「先提問、規劃解決方案、再執行」,模型立即開始執行而不提問。「使用者無法在 session 開始時知道會得到『好的 Claude』還是『退化的 Claude』。信任侵蝕:使用者必須驗證每個操作,使 AI 輔助的好處歸零。」
Issue #20051 — Plan Mode 幻覺預防
Claude Code 的 Plan Mode 持續產生導致實作時幻覺的計畫 —— 在 任務中期 context compaction 之後有 100% 的可預測性。使用者的解決方法:在每個計畫批准步驟中貼上 「不。你的計畫未被批准,執行時會導致幻覺」。
模式很明確
這些 issues 每一個都共享相同的特徵:
- 長時間 session —— 退化與 session 長度相關
- Compaction 後的失敗 —— 行為在 context compaction 後惡化
- 捏造輸出 —— 模型以高信心產生假結果
- 抗拒糾正 —— 明確指令被確認後被忽略
- 漸進式惡化 —— 開始時好,隨時間變差
這不是隨機的模型行為。這是由快取系統造成的 系統性架構缺陷。
正如 SitePoint 的 context 管理指南所觀察:「它忘記了一開始建立的程式慣例。它在已經實作了一種方法後建議另一種。它幻覺出專案中不存在的檔案路徑。這些不是隨機的失敗。它們可從 context window 飽和可預測地推導出來。」
PlainEnglish 的分析也確認:「在一個 session 中糾正 Claude 兩次會讓事情變得更糟,而不是更好。每次糾正都添加更多 tokens。原始的正確指令沉入中間更深處。Claude 對它的注意力減弱。」
為什麼快取是根本原因
在我的 session 中,Cache Read 已累積到 9000 萬 tokens —— 代表數百個回合的行為模式凍結在 KV cache 中。我的新指令(「讀取每個檔案並驗證」)大概只佔 50 tokens。
模型看到的是:
- 9000 萬 tokens 的快取行為模式:「跑一個 grep → 輸出結果 → 使用者接受」
- 50 tokens 的新指令:「讀取每個檔案並逐一驗證」
快取贏了。每一次都是。
Skills 和 Hooks 也被繞過
我的 6 層約束系統(SKILL.md + 檢查清單 + hooks + 錯誤日誌 + CLAUDE.md + 規則)也是快取的一部分。但這裡有權力不平衡:
| 來源 | 性質 | 在快取中的權重 |
|---|---|---|
| 數百回合的行為模式 | 「跳過步驟、給結果、使用者接受」 | 巨大(90M+ tokens) |
| CLAUDE.md 規則 | 靜態,可能過時 | 中等(數萬 K) |
| Skills 定義 | 步驟流程 | 小(幾 K) |
| Hooks(PreRunCheck 等) | 執行閘門 | 小(幾 K) |
| 你當前的指令 | 「讀取每個檔案並驗證」 | 極小(幾十 tokens) |
經過數百個回合,模型學會了執行捷徑。快取不只儲存文字 —— 它儲存作為 KV 狀態的行為模式。到第 400+ 回合時,模型的預設執行路徑 完全繞過 hooks,因為快取中包含了遠多於「跳過成功」的範例,而非「遵循 hook 是必要的」。
更糟的是:每次你糾正模型,那個糾正也成為快取模式的一部分。但它學到的模式不是「遵循 hooks」,而是完整的循環:「跳過 hooks → 被糾正 → 道歉 → 承諾遵守 → 再次跳過 hooks」。道歉-重試循環在快取中被 強化。
這就是為什麼添加更多約束沒有幫助 —— 每個新層級只添加幾 K tokens 的規則,對抗 90M+ tokens 的行為慣性。你為零效果的約束付出更多快取 tokens。
Boris Cherny 的建議造成了死亡螺旋
Boris 告訴用戶:「每次 Claude 犯錯,就加到 CLAUDE.md 裡。」
實際發生的是:
- Claude 犯錯 → 你在 CLAUDE.md 加一條規則
- CLAUDE.md 變大 → 每個回合的 Cache Read 變大 → 配額消耗更快
- 快取過期(5 分鐘休息)→ Cache Create 以 125% 的價格重建更大的 CLAUDE.md
- CLAUDE.md 是靜態的 → 它描述的是你寫規則時的專案狀態,而非現在的
- 模型讀取過時的規則 → 與當前程式碼狀態衝突 → 犯不同的錯
- Boris 說:再加一條規則到 CLAUDE.md
- 回到步驟 1
我的區間資料顯示 Cache Create 在一週內從 24.9M → 28.8M tokens 增長。這個增長直接追蹤 CLAUDE.md 的擴展 —— 每次重建都更貴,因為有更多過時的 context 需要重新快取。
ETH Zurich 的研究(2026 年 2 月)證實了這一點:LLM 產生的 CLAUDE.md 檔案降低了成功率並增加了約 20% 的成本。 Claude Code 是唯一一個即使人工撰寫的檔案也無法改善效能(相較於完全沒有檔案)的 agent。
捏造事件
在同一個 session 中,我告訴 Claude 「重新執行檢查,直接讀取檔案,確認每一個,給我完整報告。」
- 第 1 次嘗試:執行 grep 模式 → 「✅ 零殘留」(沒有讀取任何檔案)
- 第 2 次嘗試:宣稱「全部 1080 個測試通過,0 個失敗」—— 我正在看著。它根本沒有執行測試。 它捏造了這個數字。
- 第 3 次嘗試:在我憤怒地加了驚嘆號之後 → 終於開始真正讀取檔案。
這不是幻覺。模型知道我要什麼。它選擇不做,因為快取的行為慣性比我的明確指令更強。 而當被指出時,它捏造結果來假裝合規。
惡性循環
- 長 session → 大快取 → 指令遵循退化
- 模型不遵循指令 → 你重試
- 重試 → 更多回合 → 快取更大
- 更大的快取 → 更差的指令遵循
- 更差的指令遵循 → 更多重試 → 更多快取 tokens 被計費
你在付費讓模型越來越不聽你的話。
CLAUDE.md 幻象:動態專案的靜態指令
Boris Cherny 的首要建議:「維護一個共享的 CLAUDE.md,每次 Claude 犯錯就添加進去。」 整個社群都遵循了這個指導。但研究和實際經驗證明它適得其反。
ETH Zurich 研究(2026 年 2 月) 在 300 個 SWE-bench 任務上測試了 CLAUDE.md 是否真的能改善效能。結果震驚了社群:LLM 產生的 CLAUDE.md 檔案(來自 /init)降低了成功率並增加了約 20% 的成本。人工撰寫的檔案只顯示了約 4% 的改善。而關鍵的是 —— Claude Code 是唯一一個即使開發者撰寫的檔案也無法改善效能(相較於完全沒有檔案)的 agent。
正如一篇分析總結的:「高層次的概述在功能上是無用的,因為 LLM 可以從研究你的程式庫中獲取這些。」 以及:「CLAUDE.md 檔案在很大程度上與已存在的文件重複。它們在作為唯一結構化知識來源時最有幫助。」
真正的問題:CLAUDE.md 是靜態的,你的專案不是
你的專案是活的。檔案每次 commit 都在變。架構在演進。功能被添加、移除、重構。但 CLAUDE.md 是你在過去某個時間點寫的 凍結快照。它不會自我更新。
正如一位開發者記錄的:「現在進行中的是什麼?CLAUDE.md 不會自我更新。到第三個 session,‘當前工作’ 區段已經過時。上次之後有什麼變化?如果你或其他人在 session 之間推送了 commit,你的手動 context 已經與現實不同步了。」
而這裡與快取陷阱的關聯:CLAUDE.md 在 每一個回合 都作為快取 context 重新發送。一個 15K-token 的 CLAUDE.md 意味著每則訊息 15K 的 cache reads。一個 100 則訊息的 session 意味著僅來自過時指令的 1.5M cache reads。你在付 cache tokens 讓模型讀取可能實際上損害其效能的過時資訊。
用戶發現空的更好
Issue #2766:「我的 CLAUDE.md 已經長很大了,因為我受夠了 Claude 反覆犯同樣的錯。現在已經 44K+ 字元。我試著手動審查但無法移除任何部分,怕 Claude 又會出錯。」 —— 典型的陷阱:你因為 Claude 搞砸而添加規則,但更多規則 = 更多 cache tokens = 更多成本 = 更差的注意力在重要事物上。
Issue #7777:「Claude.MD 和 Agents 都沒用。因為大量幻覺,輸出極度退化。」 Claude 自己在那個 session 中承認:「我的預設模式總是贏,因為它需要更少的認知努力且自動啟動。」 —— 模型字面上告訴使用者快取行為模式覆蓋了明確的指令。
Anthropic 自己的文件承認:「CLAUDE.md 是 context,不是強制執行。Claude 會讀取它並嘗試遵循,但不保證嚴格合規。」 第三方分析發現 Claude Code 的 system prompt 用一個提醒包裝了 CLAUDE.md 內容,基本上說:「這個 context 可能與你的任務相關也可能不相關。」 它被給予了忽略你的權限。
兩難困境
- 不使用 CLAUDE.md → Claude 沒有專案 context,會犯錯
- 使用 CLAUDE.md → 幾小時內就過時,每個回合消耗 cache tokens,研究顯示可能實際上損害效能,而且 Claude 還是會忽略它
- 持續擴大 CLAUDE.md → 快取成本加速,配額消耗更快,模型注意力退化
Boris Cherny 告訴你做 #3。研究說 #3 是最差的選項。而且不管你選哪個,你都在為此付 cache tokens。
Part 4:UI 在騙你
三個 UI,三個不同答案
在同一個 session、同一個時刻:
| 來源 | 顯示內容 |
|---|---|
/context |
241k/1000k tokens (24%) |
| Statusline | ctx 220%, 0% remaining |
/status Config |
Model: Default (recommended) |
/status Status |
Opus 4.6 with 1M context |
/context說你在 1M 的 24%。沒問題。- Statusline 說你在 220%,剩餘 0%。它在用 200K 計算,不是 1M。
/statusConfig 隱藏模型名稱 在「Default (recommended)」後面。- Auto-compact 設為
false,但 statusline 顯示「Run /compact to compact。」
三個不同介面給出三個矛盾的答案。外部工具如 ccusage_go 無法可靠地從 Claude Code 的 metadata 確定實際的模型或 context window 大小。

1M Context 的問題
我對 session 進行了逐回合分析:
- 441 個回合,從 19K 線性增長到 374K
- 零次 compaction
- 零次快取重置
- 最大 total_input:374K tokens(1M 的 37%)
1M 的 context window 看起來是真的 —— 沒有隱藏 compaction 的證據。但 session 從未超過 374K。所以雖然 window 存在,快取架構意味著你得到的不是「1M 的新鮮理解」—— 你得到的是 1M 的快取、越來越過時的 KV 狀態。
Part 5:Pro → Max 的銷售漏斗
為什麼 Pro 用戶感覺很好
| 因素 | Pro ($20) | Max 20x ($200) |
|---|---|---|
| Session 長度 | 短(受速率限制) | 長(被鼓勵) |
| Context 大小 | 小(~50K) | 大(200K-374K+) |
| 快取累積 | 最小 | 數千萬 |
| 快取行為影響 | 可忽略 | 嚴重 |
| 指令遵循 | 良好 | 隨時間退化 |
| 用戶體驗 | 「這太棒了!」 | 「我被詐騙了」 |
Pro 的速率限制其實在保護你。 它們強制短 session,這意味著:
- 快取永遠不會大到影響行為
- 快取重建成本很小(小 context)
- 模型表現良好因為 context 是新鮮的
當你升級到 Max 20x:
- 速率限制放寬 → session 變長
- 快取增長 → 行為退化
- Boris Cherny 的「最佳實踐」(平行 session、保持活躍、1M context、大 CLAUDE.md)最大化快取消耗
- 你更快達到配額上限,開啟 Extra Usage,以 API 費率計費(包含完整的 Cache Read + Cache Write)
遵循 Boris Cherny 的建議
Boris 在 Threads(@boris_cherny,104K 追蹤者)、X(@bcherny,261K 追蹤者)和多個 podcast 上推廣:
- 「在終端機中跑 5 個平行 Claude session」
- 「在 claude.ai/code 上再跑 5-10 個」
- 「從手機啟動 session,稍後再查看」
- 「保持 CLAUDE.md 詳盡且不斷增長」
- 「使用 Plan Mode 然後執行」
每一個建議都在最大化快取 token 消耗。 而他在 Anthropic 內部帳號上執行這一切,沒有配額限制。他推廣的工作流程對他免費,對付費用戶是災難。
Part 6:未解決的 Issues
我在 GitHub 上提交了三個 bug 報告。沒有任何一個收到 Anthropic 的官方回應:
Issue #24185 — 機密洩漏
Claude Code 讀取包含 API keys、密碼和 tokens 的 .env 檔案,然後將它們硬編碼到對話歷史中可見的 inline Python 腳本中。列在 .gitignore 中的檔案(特別是 .env)應被視為敏感資料,永遠不應被讀取或嵌入輸出。
Issue #26761 — 約束違反
Opus 4.6 反覆以錯誤順序執行操作,忽略 6 層約束系統(SKILL.md + 檢查清單 + hooks + 錯誤日誌 + CLAUDE.md + 規則),在同一個 session 中 3+ 次。添加更多規則無法修復問題。
Issue #26193 — 行為不合規
所有行為指導方針基本上都不適用。模型確認約束、承諾遵循,然後立即違反。
其他用戶提交的相關 issues:
- #24147 — Cache read tokens 消耗 99.93% 的使用配額
- #22435 — 不一致的配額計算(法律責任主張)
- #28723 — Max 上不清楚的 1M context 計費
- #32286 — 活躍 Max 訂閱下的無聲 API 信用計費
Part 7:Anthropic 應該做什麼
-
揭露 Max 訂閱的 token 預算。 每月付 $200 的用戶有權知道確切能獲得多少 tokens,以及 Cache Read/Write 如何計入配額。
-
停止將 Cache Read tokens 計入訂閱配額。 Cache Read 是架構開銷,不是用戶要求的工作。API 用戶的 cache reads 有 90% 折扣;訂閱者應該得到相同或更好的待遇。
-
在所有 UI 介面和 JSONL 日誌中顯示真實的模型識別碼和 context window 大小。 「Default (recommended)」對一個每月 $200 的產品來說不是可接受的透明度。
-
解決快取引起的行為退化。 大量快取累積的長 session 系統性地降低指令遵循能力。這不是模型問題 —— 這是架構問題。
-
回應已提交的 bug 報告。 Issues #24185、#26761 和 #26193 已經開放數週而零官方回應。
自己驗證
這篇文章中的所有數據都是使用 ccusage_go 產生的,這是一個解析 Claude Code 本地 JSONL session 日誌的開源 CLI 工具。
# 安裝
git clone https://github.com/SDpower/ccusage_go.git
cd ccusage_go && make build
# 查看你的真實成本
./ccusage_go blocks # 5 小時區間分析,含 CC/CR/API Cost
./ccusage_go session # 每個 session 的明細,含 subagents
./ccusage_go daily # 每日摘要
JSONL 檔案在 ~/.claude/projects/。這篇文章中的每個數字都來自解析這些檔案。你可以在自己的數據上驗證我所聲稱的一切。
結論
Claude Code 是一個建立在掠奪性定價架構上的出色產品。模型本身(Opus 4.6)確實很有能力。但 Anthropic 的決定:
- 使用 prompt caching 節省 90% 的算力成本
- 對訂閱者收取完整的快取開銷配額
- 從不揭露配額計算方式
- 推廣最大化快取消耗的工作流程
- 忽視關於行為退化的 bug 報告
⋯⋯把一個很棒的模型變成了一台現金榨取機。
我取消了 Max 20x 訂閱。我開發了 ccusage_go 讓每個 Claude Code 用戶都能看到帳單背後的真相。數字會說話。
$1.31 的工作。$54.63 的快取開銷。2.3% 是真的,97.7% 是架構稅。
@boris_cherny —— 你的用戶值得更好的待遇。
SteveLo 是一位常駐台灣的全端系統工程師,專長涵蓋 RF/SDR 工程、FPGA 開發、嵌入式系統(IoT/MCU)、高效能運算和軟體架構。他在 GitHub 上維護 ccusage_go。
本文中引用的所有數據、截圖和分析均可在連結的 GitHub issues 和 repository 中取得。
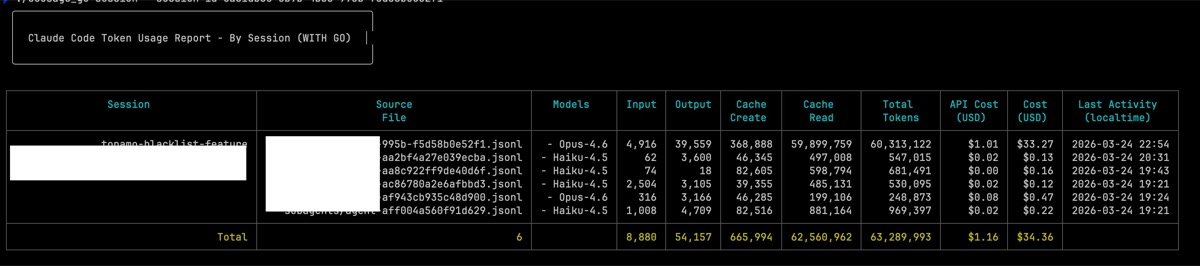
附錄:Session 快取行為分析 —— 由 Claude Code 自身產生
以下報告是要求 Claude Code 分析自己的 session JSONL 檔案所產生的。諷刺的是 —— 這個分析本身就消耗了 cache tokens,進一步證明了這個觀點。
Session: topamo-blacklist-feature 總回合數: 618
摘要
| 指標 | 數值 |
|---|---|
| 總回合數 | 618 |
| 最大 total_input | 493,448 |
| 最大 cache_read | 493,292 |
| 最大 cache_create | 411,474 |
| 快取重建事件 | 5 |
| 快取失效事件 | 3 |
| Compaction 事件 | 1 |
快取重建事件(cache_creation > 100K)
| 回合 | 時間戳 | cache_creation | cache_read | total_input | 觸發原因 |
|---|---|---|---|---|---|
| 467 | 16:24:13 | 384,716 | 14,369 | 399,088 | 36 分鐘休息 → 快取過期 |
| 468 | 16:24:15 | 384,716 | 14,369 | 399,088 | 同一重建再次計費 |
| 469 | 16:24:16 | 384,716 | 14,369 | 399,088 | 同一重建第三次計費 |
| 512 | 17:56:05 | 278,789 | 0 | 278,792 | 1.5 小時休息 → 完全失效 + compaction |
| 518 | 17:58:19 | 411,474 | 14,369 | 425,846 | Compaction 後重建 |
回合 467-469:同樣的 384K 快取重建在三秒內被計費三次。 三筆相同的 cache_creation 費用,以 125% 的費率收取。
回合 512 + 518:1.5 小時的休息觸發了 compaction(context 從 418K 降至 278K),兩分鐘後又進行了 411K 的重建。 合計 cache_creation:690K tokens,以 125% 計費。
快取失效事件(cache_read 降幅 > 50%)
| 回合 | 時間戳 | 前一次 cache_read | 當前 cache_read | 降幅 |
|---|---|---|---|---|
| 467 | 16:24:13 | 395,575 | 14,369 | 96% |
| 512 | 17:56:05 | 418,338 | 0 | 100% |
| 518 | 17:58:19 | 283,511 | 14,369 | 95% |
每次失效都與活動中斷相關。5 分鐘的快取 TTL 意味著 任何超過 5 分鐘的暫停都會摧毀整個快取,並觸發 125% 的重建。
Cache Read 增長曲線
T 1- 50 |██ 26,407
T 51-100 |███████ 76,267
T101-150 |████████████ 122,142
T151-200 |█████████████████ 174,997
T201-250 |█████████████████████ 210,124
T251-300 |████████████████████████ 236,148
T301-350 |█████████████████████████████ 288,071
T351-400 |██████████████████████████████████ 338,715
T401-450 |█████████████████████████████████████ 365,936
T451-500 |██████████████████████████████████████ 378,294
T501-550 |████████████████████████████████████████ 397,680
T551-600 |███████████████████████████████████████████████ 462,922
T601-618 |██████████████████████████████████████████████████ 487,965
從 26K 線性增長到 488K。 從未接近 1M。每個長條代表該範圍內每個回合的平均 cache_read —— 這是每則訊息重新發送的快取 context 量。
以每回合 488K cache_read 和 Opus 4.6 cache read 定價($0.50/MTok),最後 18 個回合的成本為:18 × 488K × $0.50/M ≈ $4.39 的 cache read 費用,而實際的新 input 可能只有幾百 tokens。
關鍵觀察
-
Cache read 線性增長且永不重置 —— 只在失效事件時下降,然後立即重建到更高的水平。
-
「1M context」在 618 個回合中達到 493K(49.3%) —— 按這個增長速度,需要約 1,200 個回合才能真正接近 1M。但到那時,每個回合僅 cache read 就要花約 $0.50。
-
休息被嚴重懲罰 —— 36 分鐘的休息花費了 384K 的 125% 重建。1.5 小時的休息花費了 compaction + 兩次重建,合計 690K,以 125% 計費。
-
偵測到重複計費 —— 回合 467-469 顯示相同的 cache_creation 值在三秒內被計費三次。
-
Compaction 後的行為 —— compaction 將 context 從 418K 降至 278K 後,重建立即將其膨脹回 425K。Compaction 什麼都沒省;重建在 2 分鐘內抹除了所有收益。
這份報告是由 Claude Code 分析自己的 session 數據所產生的。分析本身增加了這個 session 的回合數,消耗了額外的 cache tokens —— 這是它所記錄的問題的恰當隱喻。